† Nonexperimental evaluation designs are not addressed in this guide because they often cannot demonstrate that the response preceded the decline in the problem, and because they are particularly poor at ruling out alternative explanations. Randomized evaluation designs are not addressed, either. Though powerful for studying generic interventions to apply to a class of problems, they are generally unsuited for operational problemsolving in which the primary interest is to reduce a specific problem. The publications listed under "Recommended Readings" provide information about these and other designs not described here.
An evaluation design is a systematic strategy, coordinated with the response, for organizing when and where data collection will occur. If you develop the evaluation design along with the response, the evaluation is more likely to produce useful information. Waiting until after you have implemented the response to decide how you will evaluate it makes it more difficult to determine whether it was effective.
There are many types of evaluation designs (see the "Recommended Readings" section). We will discuss two common, practical designs: the pre-post and the interrupted time series. Appendix B describes designs using control groups: the pre-post with a control group, and the multiple time series. Table 2 summarizes the relationships among these four designs:
| Single Measurement Before and After | Multiple Measurements Before and After | |
|---|---|---|
| No Control Group | Pre-post | Interrupted time series |
| Control Group | Pre-post with a control group | Multiple time series |
Table 2: Types of Evaluation Designs
The simplest pre-post design involves a single measurement of the problem both before and after the response. You then compare the measures. As we will see, this design is sometimes adequate for determining if the problem declined, but is insufficient for determining if the response caused the decline.†
† In most evaluation research, a statistical significance test is used to determine if the difference between the pre- and post-response measures is likely due to chance. In other words, one alternative explanation is that normal random fluctuations in the problem level caused the difference between the before and after measures. A statistical significance test is most useful when the difference is small but nevertheless meaningful, and the number of problem events before the response was small. In such circumstances, normal random fluctuations are a potential cause for the change in the problem. Because of the highly technical nature of significance testing, this guide does not cover it. Readers interested in significance testing can learn more from most introductory statistics texts, the documentation accompanying statistical software, or statisticians and social scientists at local universities.
Figure 4 illustrates the results of a pre-post design. The first bar shows the level of the problem before the response, and the second bar shows the level after. The difference between the heights of the bars represents the change in the problem. Though this example shows a decline, there is no guarantee; there could be an increase or no change in the problem (see Appendix A for an illustration).
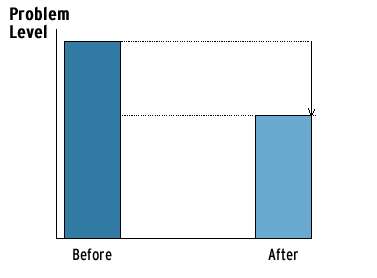
Fig. 4. Impact measurement in a pre-post design
The pre-post design can establish a relationship by demonstrating that there was less of a problem with the response than without it. It also helps to demonstrate that the response preceded the decline, because the response occurred between the two measures. However, if the problem level normally fluctuates, then what you see as a decline may simply be a normal low before a return to a higher level. Variations on this simple design include taking measures at the same time of the year, to account for seasonal fluctuations, and taking two or three pre-measures and two or three postmeasures, to account for other fluctuations.
As we have seen, this design is weak at ruling out alternative explanations for a decline in a problem. This is because something else may have caused the response and/or the decline. Consider two examples in which a pre-post design can give misleading results.
In the first example, suppose that, overall, the problem was declining, and this decline started before the pre-response measurement. If you knew this, then you would conclude that the decline would have occurred even if you had done nothing about the problem. Absent information about the downward trend, you would have false confidence in the response (Appendix A illustrates this in greater detail).
In the second example, the pre-post results show no change in the problem (or even a slight increase in it). Based on these results, you might believe the response was ineffective. However, if you knew that the long-term trend was for the problem to get much worse, then you might realize that the response might have averted much of that decline. In this case, the pre-post design gives the false impression that the response was ineffective.
When examining pre-post results, you should also consider when the response is implemented. Many problems fester for long periods, with many ups and downs. Even without any intervention, such problems fluctuate, though the fluctuations are around a constant average. Problem-solving efforts are more likely to be launched when problems are at their peak, and due to decline anyway. Thus, a decline may be due to this automatic process rather than to the response.† Next, we will examine designs that can rule out this particular alternative explanation.
† The technical term for this automatic process is "regression to the mean."
The interrupted time series design is far superior to the prepost design because it can address many of the issues discussed above. With this design, you take many measures of the problem before the response. This lets you look at the pre-response trend in the problem. You then take many measures of the problem after the response. Comparing the before trend with the after trend provides an indicator of effectiveness. This is feasible using reported crime data or other information routinely gathered by public and private organizations. It is more difficult if you have to initiate a special data collection effort, such as a public survey.
The basic approach is to use repeated measures of the problem before the response to forecast the likely problem level after the response. If the difference between the forecast and the measures taken after the response is significant and negative, this indicates that the response was effective (see Appendix A).
This design provides strong evidence that the response preceded the problem's decline, because you can identify preexisting trends. If the procedures for measuring the problem have not changed, this design rules out most alternative explanations for the decline, including the automatic-process explanation.
You should note that it is the number of measurement periods that matter, not the length of time. So, for example, annual data for the three years before and after the response are far less helpful than measurements for the 30 months before and after the response, even though less time has elapsed.
You might be tempted to take this to the extreme. If monthly data are better than annual data, why not collect weekly, daily or even hourly data? The answer is that, for most crimes, as the time interval becomes shorter, the number of crimes per interval becomes too small to derive meaningful conclusions. If the number of events is extremely large (as is sometimes the case when using calls-for-service data for large areas), then very short intervals might be useful. But if the number of events is very small (as with homicide or stranger-stranger rape), then you might have to use large intervals.
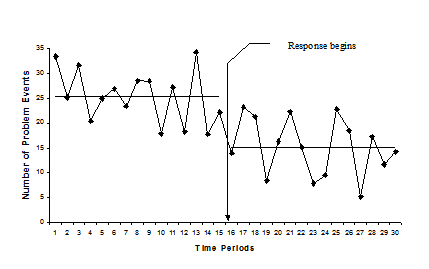
Fig. 5. Impact measurement in an interrupted time series design
In Figure 5, the points on the graph represent measures of the problem taken at different times. The horizontal lines represent the trend (in this case, the average or mean) for the before and after periods. There is much variation around the mean values for both periods, and this variation can sometimes obscure response effects.
Since the trend is flat, the forecast is a horizontal-line projection based on the average number of incidents per time period. A comparison of the average problem level before and after the response shows a decline. If the problem had been trending up, then you would use an upward sloping projection and would have to calculate the slope (Appendix A provides an example). The more time periods you examine before the response, the more confident you can be that you know the problem's trajectory. The more time periods you examine after the response, the more confident you can be that the trajectory has changed. The calculations involved in analyzing an interrupted time series design can become quite involved, so if you have a lot riding on the evaluation's outcome, it may be worthwhile to seek expert help.
Ideally, the only difference between the time periods before and the time periods after the response is the presence of the response. If this is the case, then conclusions based on this design have a high degree of validity.
The major weakness of the interrupted time series design is the possibility that something else that occurred at the same time the response began caused the observed change in the problem. To rule out this alternative explanation, you can add a second time series for a control group (see Appendix B).
Even if you are interested in determining only whether the problem declined (and have little interest in establishing what caused the decline), an interrupted time series design is still superior to a pre-post design. This is because an interrupted time series design can show whether the problem went down and stayed down. As noted above, problems can fluctuate, so it is desirable to determine the decline's stability. The longer the time series after the decline, the greater your confidence that the problem has been eliminated or is stable at a much reduced level.
Though interrupted time series designs are superior to prepost designs, they are not always practical. Here are five common reasons for this:
Under these conditions, a pre-post design might be the most practical alternative.
Though we have examined pre-post and interrupted time series designs separately (here and in Appendix B), in many cases, you can use two or more designs to test a response's effectiveness. This is particularly useful if you have several measures of the problem (for example, reported crime data and citizen survey information) for different periods. Using a combination of designs selected to rule out particularly troublesome alternative explanations can be far more useful than strictly adhering to a single design.
In considering what type of design or combination of designs to use, you should bear in mind that you cannot rule out all alternative explanations for a problem's decline. Based on your available resources, you should select the simplest design that can rule out the most obvious alternative explanations. In other words, you should anticipate such explanations before you select the design. Once again, your analysis of the problem should give you some insight.
Before addressing spatial displacement of crime and disorder, and spatial diffusion of crime prevention benefits, we need to recall that there are two possible evaluation goals. The first is to demonstrate that the problem declined. The second is to have sufficient evidence to legitimately claim that the response caused the decline. The second goal is important only if you are going to use the response again. If so, you will need evidence that the response is effective–that it causes problems to decline. If you do not intend to use the response again (or to recommend it to others), then there is no real need to gather sufficient evidence to demonstrate that it caused the decline. In this case, you can say that there was a problem, you implemented a response, and the problem declined, but you do not know if the decline was due to the response or to other factors.
Spatial Displacement of Crime or Disorder, and Spatial Diffusion of Crime Prevention Benefits
A common concern about problem-solving responses is that they will result in spatial displacement of crime or disorder–the shifting of crime or disorder from the target area to nearby areas. This possibility is probably not as great as is imagined.6 However, although displacement is far from inevitable, you should consider the possibility. In addition, there is increasing evidence that some responses have positive effects that spread beyond the target area. 7 This is called spatial diffusion of crime prevention benefits. Though not all responses result in benefits beyond those planned for, some do, and you should also consider this possibility. If you do not account for displacement and diffusion, you could produce misleading evaluation results. To see how this can occur, and to learn how to address it, let's use a burglary problem as an example.
Suppose you have a 150-unit apartment complex that is beset by burglaries (we will call this the target complex). Across the street is a 120-unit complex that has some burglaries, but not as many as the target complex (we will call this the neighboring complex). Though built at different times, with somewhat different architectural designs, the complexes house occupants who are very similar with regard to income, race and number of children. Four miles away, there is a third, 180-unit complex that is also similar to the target complex. Now imagine that reported crime data show an average of 20 burglaries per month in the target complex before the response, and an average of 10 after the response (a 50 percent decline). Though this looks like a major success, you want to determine if the decline would have occurred regardless of the response.
Scenario A. You pick the neighboring complex as a control (see Appendix B), and you find that it had an average of seven burglaries per month before the response, and an average of 12 after the response. A control group is supposed to show what would have occurred absent a response, so you conclude–based on the increase in control group burglaries–that the target complex would also have experienced an increase, were it not for the response. Is this a valid conclusion? Maybe not. If displacement has occurred, about a quarter of the burglaries that were occurring in the target complex are now occurring in the neighboring complex. The response may have been successful, but not as successful as you thought. If crime or disorder shifts to a control area, then response success will be artificially inflated.
Scenario B. Burglaries in the neighboring complex drop from an average of seven a month before the response to an average of two after the response (a 71 percent decline). If the neighboring complex is the control group, then, on a percentage basis, the target complex did worse. Perhaps you would have been better off doing nothing.
But suppose that what really occurred was that the same burglars had been preying on both complexes. After the response, they decided to play it safe and reduced their efforts in both complexes. This means that instead of failing, the response was far more successful than anticipated. There was a diffusion of benefits from the target complex to the neighboring complex. Thus, using the neighboring complex as a control led you to vastly underestimate your response's success. If benefits extend to a control area, then response success will be artificially deflated.
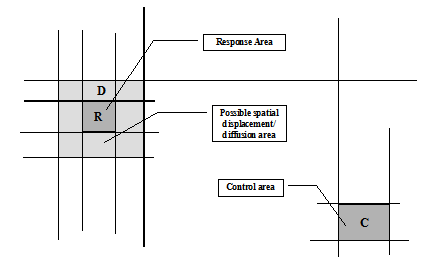
Fig. 6. Handling possible spatial displacement and diffusion
Scenario C. You pick the complex four miles away as the control group, and use the neighboring complex to determine if displacement or diffusion occurred. If distance prevents the third complex from experiencing positive or negative effects, then it is a useful control group.
Figure 6 shows the relationship between a response area (R), a control area (C) and a displacement/diffusion area (D). C is not connected to the other areas, while D surrounds R. Such an arrangement is useful as long as the three areas are similar, and the control area is insulated from the response area, while the displacement/diffusion area is not.
Though distance can provide insulation, it is no guarantee. If R, C and D are public housing complexes, and if the public housing authority moves tenants among them, then offenders in R will probably know about C, and may have acquaintances there. Consequently, C could be subject to displacement or diffusion. On the other hand, two areas may be close together, yet well insulated if there are major barriers to movement (e.g., rivers, canyons or highways).
Comparing the target complex with the third complex gives you an estimate of the benefits of your response. Comparing the neighboring complex with the third complex tells you if displacement or diffusion occurred. You can combine the results to estimate the net effect (see Appendix C). If targetarea burglaries dropped by 10, control-area burglaries dropped by three, and displacement/diffusion-area burglaries dropped by two, then the net reduction in burglaries per month would be -10 + 3 - 2 = -9. If displacement/diffusion-area burglaries increased by two, then the net reduction in burglaries per month would be -10 + 3 + 2 = -5. The basic principle is that you remove from the change in the problem the change that would have occurred anyway. You then increase the reduction in the problem if diffusion occurs, or decrease the reduction if displacement occurs.
This guide has introduced some basic principles of assessing the effectiveness of problem-solving efforts. All such evaluations require valid, systematic measures of the problem taken both before and after the response. There are two possible goals for any problem-solving evaluation. The first is to demonstrate that the problem declined enough to call an end to the response. This is the most basic requirement of an evaluation. In many circumstances, it is also useful to determine if the response caused the decline. If you anticipate using the response again on similar problems (or on the same problem, if it returns), then it is important to make this determination. This requires an evaluation that can rule out the most likely alternative explanations–one using either an interrupted time series design or a control group (see Appendix B). The control group tells you what the problem level would likely be, absent the problem-solving effort.
You should compare the results of the impact evaluation with those of the process evaluation to determine whether the response was implemented as planned, and what its impact was. With this information, you can adjust the response or craft a new one. This information should also aid others when they address similar problems.
A recurring theme in this guide is that the evaluation design builds on knowledge gained during the problem analysis. Competent evaluations require detailed knowledge of the problem so that you can develop useful measures and anticipate possible reasons for a decline in the problem following the response.
Evaluating prevention efforts can be extremely complex. For small-scale problem-solving efforts, in which the costs of mistaken conclusions are not serious, and weak causal inferences are tolerable, the information provided here should be sufficient. If, however, there is a lot riding on the outcome, it is important to show whether the response caused the drop in the problem, or there are serious consequences from drawing the wrong conclusions, then you should seek professional help in developing a rigorous evaluation. Once you have identified a problem, you should decide, as soon as possible, whether to enlist an outside evaluator's support to take adequate before measures and develop a rigorous design.


You may order free bound copies in any of three ways:
Online: Department of Justice COPS Response Center
Email: askCopsRC@usdoj.gov
Phone: 800-421-6770 or 202-307-1480
Allow several days for delivery.
Send an e-mail with a link to this guide.
* required
Error sending email. Please review your enteries below.


